I am converting some Js code to Reason, and there some tabular datastructures, much like SQL database dumps.
On the Javascript side
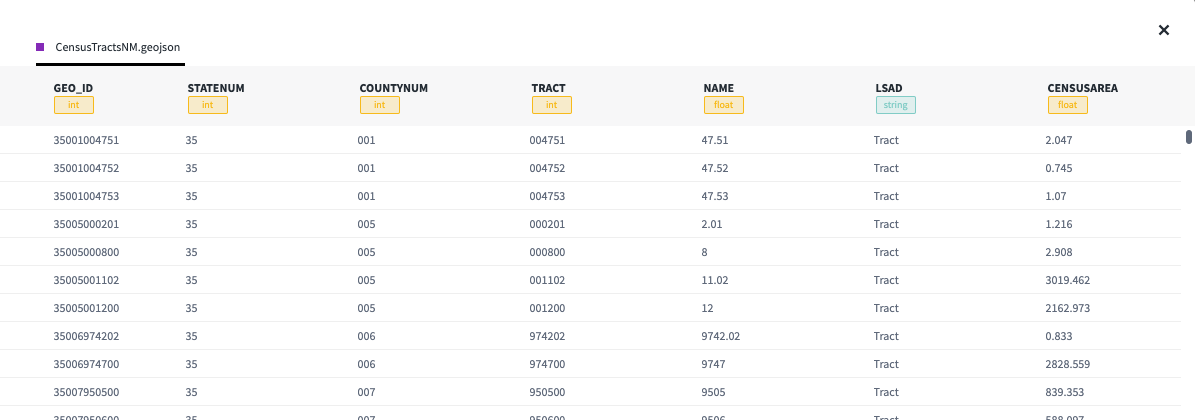
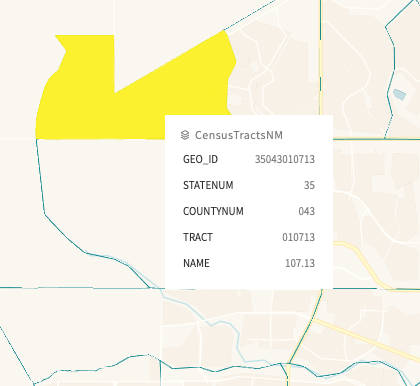
Within a redux state tree there is a ‘datasets’ object, which is kinda like a relational database dump because it has rows, field names, and field types. Imagine the user uploads some CSV data and it gets parsed by javascript. There are be arbitrarily many rows and fields, and the fields can occur in any order in an indexed array. There is a runtime type detector that flags each field like “string”, “geojson” etc. (homegrown janky static typing haha). However, there known set of possible field types. At the top level it looks like this as json:
{ datasets: { "id" : { data: [...], fields: [...] }}}
In Reason Land
I’m not parsing the CSV data in Reason (yet). Rather I want to do some business logic on the datasets object in reason land. First, I want to parse the datasets object into strongly typed reason data. As soon as I realized the order of fields is unknown, and the number of fields is unknown, I ran into a bit of a mental block.
1st Idea: Use bs-json and start implementing Decoders to convert each level of the json object into a specific Reason type. Writing the decoders will result in the ultimate shape of the type definitions in reason.
2nd Idea: Is this an application for Functors? I want to inspect a json object, and output a new module which represents that dataset’s layout, field order and field types, exactly. So something that generates a new module is a Functor, right?
Do you recommend I be going down rabbit hole #1 or #2, a combination, or something else entirely?
Thanks